
Better weather forecasts for the iPhone
May 2, 2008 at 10:52 PM by Dr. Drang
I’ve come to hate the weather application built into the iPhone. The graphics are cute, but the information is limited: current temperature, highs and lows for today and the next five days, and a little icon that tries to describe the cloudiness/sunniness/raininess/snowiness/fogginess for each day. It’s the icon that gets to me. A spring day in the Midwest can seldom be described with just one picture, because the weather changes too quickly. What I want is something more granular—a forecast for this afternoon, overnight, tomorrow, and tomorrow night. Predictions beyond that are OK, but I don’t really believe them.
So I set about making a web app, geared to the iPhone, that would give me that information. Here’s what it looks like:

It screen-scrapes a National Weather Service page that gives a detailed text forecast for the location of your choice. The full page looks like this:
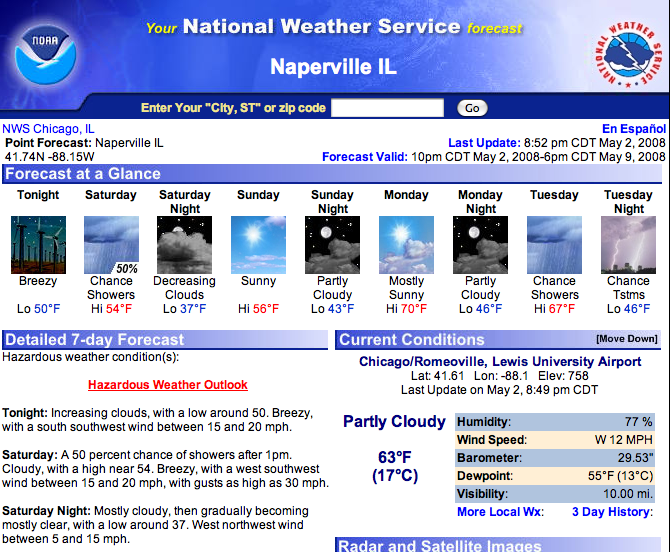
I suppose I could have grabbed the part of the page that has the icons, but I like having the wind speed and other information that’s in the text forecast.
For my first go-round, I’ve hard-coded my home town into the CGI script, which I’ve called nws-naperville.cgi. It’s a Python program that uses the very cool Beautiful Soup library for scraping the NWS page.
1: #!/usr/bin/python
2:
3: from BeautifulSoup import BeautifulSoup
4: import urllib
5:
6: # Query the NWS site and get the page of results for Naperville.
7: f=urllib.urlopen('http://forecast.weather.gov/zipcity.php', urllib.urlencode({'inputstring' : '60565'}))
8: page = f.read()
9:
10: # Parse the HTML.
11: soup = BeautifulSoup(page)
12:
13: # Pluck the forecast from below the "Detailed 7-day Forecast" banner.
14: forecastItem = repr(soup.find('td', { 'width' : '50%', 'align' : 'left', 'valign' : 'top'}))
15: start = forecastItem.find('<b>')
16: forecast = forecastItem[start:-17]
17:
18: # Construct the page.
19: print "Content-type: text/html\n"
20:
21: print ''' <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"><html>
22: <html>
23: <head>
24: <title>Naperville Forecast</title>
25: <meta name="viewport" content="width = device-width" />
26: <style type="text/css">
27: body {
28: font-family: Sans-Serif;
29: font-size: large;
30: }
31: h1 {
32: font-size: x-large;
33: }
34: </style>
35: </head>
36: <body>
37: <h1>Naperville Forecast</h1>'''
38:
39: print forecast
40:
41: print '''</body>
42: </html>
43: '''
Lines 7 feeds one of Naperville’s zip codes to the PHP script that generates the NWS forecast page, and Line 8 gathers up the contents of that page. Beautiful Soup then parses the page on Line 11, and the detailed text forecast is pulled out of the page in Lines 14-16. From that point on, it’s just a matter of generating an HTML output page with the forecast embedded in it. Very simple after Beautiful Soup does the heavy lifting.
I’ve put the script in my cgi-bin directory, and I’ve added a link to it to my iPhone bookmarks. Maybe I’ll get around to creating an icon for the iPhone homepage later.
An obvious improvement to the script would be to generalize it to handle other cities. Fortunately, the NWS’s zipcity.php script can accept “City, State” input as well as zipcodes, which makes searching much easier with no additional work from me. Unfortunately, zipcity.php seems to call different servers depending on where the requested city is. If the requested city is in Arizona, California, Idaho, Montana, Nevada, New Mexico, Oregon, Utah, or Washington, the search is handled by the Western Region Headquarters server (wrh.noaa.gov), which seems to handle redirects and ambiguous city names in ways that are different (and, in my opinion, stupider) than the way the other regional servers work. I had to spend way more time learning about these differences and figuring out how to deal with them than I should have.
Here’s the HTML for simple web page that asks the user to enter a zipcode or city and state. I hope it’s clear from Line 22 that the city and state have to be separated by a comma and the state should be given as a two-letter abbreviation.
1: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"><html>
2: <html>
3: <head>
4: <title>Get Forecast</title>
5: <meta name="viewport" content="width = device-width" />
6: <style type="text/css">
7: body {
8: font-family: Sans-Serif;
9: font-size: large;
10: }
11: h1 {
12: font-size: x-large;
13: }
14: input {
15: font-size: large;
16: }
17: </style>
18: </head>
19: <body>
20: <h1>Get Forecast</h1>
21: <form method="get" action="http://www.leancrew.com/cgi-bin/nws.cgi">
22: Zip code or City, ST:
23: <input type="text" name="inputstring" value="" /><br />
24: <input type="submit">
25: </form>
26: </body>
27: </html>
I call this page forecast.html and have bookmarked this link to it on my iPhone. As you can see on Line 21, it calls a CGI script called nws.cgi:
1: #!/usr/bin/python
2:
3: from BeautifulSoup import BeautifulSoup
4: import urllib, os
5:
6: def followPage(origPage):
7: "Recursively follow JavaScript redirects to the final page."
8: pos = origPage.find('<script>document.location.replace')
9: if pos == -1:
10: return origPage
11: else:
12: start = origPage.find("('", pos) + 2
13: stop = origPage.find("')", start)
14: newurl = 'http://www.wrh.noaa.gov' + origPage[start:stop]
15: f = urllib.urlopen(newurl)
16: newPage = f.read()
17: f.close()
18: return followPage(newPage)
19:
20: # Start the script.
21:
22: # Where are we getting the forecast from?
23: place = urllib.unquote_plus(os.environ['QUERY_STRING'].split('=')[1])
24:
25: # Query the NWS site and get the page of results.
26: f=urllib.urlopen('http://forecast.weather.gov/zipcity.php', urllib.urlencode({'inputstring' : place}))
27: page = f.read()
28: f.close()
29:
30: # If the above URL returns a JavaScript redirect instead of a forecast page,
31: # follow the redirect.
32: page = followPage(page)
33:
34: # If the search string is ambiguous, choose one of the possiblities presented.
35: if page.find('More than one match was found') != -1:
36: soup = BeautifulSoup(page)
37: # We'll use the first link if we can't find a better fit.
38: link = soup.h3.nextSibling['href']
39: linkTags = soup.h3.parent.findAll('a', href=True)
40: # print linkTags
41: # Look for an exact match of the city name.
42: for tag in linkTags:
43: if tag.string.split(',')[0].lower() == place.split(',')[0].lower():
44: link = tag['href']
45: # print tag.string
46: newurl = 'http://www.wrh.noaa.gov' + link
47: f = urllib.urlopen(newurl)
48: page = f.read()
49: f.close()
50: # If it's a JavaScript redirect, follow the redirect to get the forecast.
51: page = followPage(page)
52:
53:
54: # Parse the HTML.
55: soup = BeautifulSoup(page)
56:
57: # Pluck the city and state from the "Point Forcast" line.
58: cityItem = repr(soup.find('td', {'align' : 'left', 'valign' : 'center'}))
59: start = cityItem.find('Point Forecast:</b>') + 19
60: stop = cityItem.find('<br', start)
61: city = cityItem[start:stop].strip()
62:
63: # Pluck the forecast from below the "Detailed 7-day Forecast" banner.
64: forecastItem = repr(soup.find('td', { 'width' : '50%', 'align' : 'left', 'valign' : 'top'}))
65: start = forecastItem.find('<b>')
66: forecast = forecastItem[start:-17]
67:
68: # Construct the page.
69: print "Content-type: text/html\n"
70:
71: print '''<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"><html>
72: <html>
73: <head>
74: <title>%s Forecast</title>
75: <meta name="viewport" content="width = device-width" />
76: <style type="text/css">
77: body {
78: font-family: Sans-Serif;
79: font-size: large;
80: }
81: h1 {
82: font-size: x-large;
83: }
84: </style>
85: </head>
86: <body>
87: <h1>%s Forecast</h1>''' % (city, city)
88:
89: print forecast
90:
91: print '''</body>
92: </html>
93: '''
As you can see, it’s about twice as long as nws-naperville.cgi, and virtually all of the additional lines are the idiosyncrasies of the Western Region’s server. The followPage function on Lines 6-18 deals with the (sometimes repeated) JavaScript redirects, and Lines 35-51 deal with the stupid way that server handles ambiguous city names.
[Aside and rant: Here’s an example of the stupidity. If you ask for the forecast for “Phoenix, AZ,” you don’t get the forecast for Phoenix; you’re asked to be more specific. Do you want
- Phoenix, AZ;
- Phoenix Acres Trailer Park, AZ;
- Phoenix Mobile Home Park, AZ;
- Phoenix West Mobile Home Park, AZ;
- South Phoenix, AZ; or
- The Phoenix-Scottsdale Mobile Home Park, AZ
This result is, of course, a sad commentary on the Phoenix area, but it’s an even sadder commentary on whoever programmed the Western Region’s server. The other regional servers handle this ambiguity—which isn’t really an ambiguity, since you can’t get any more specific than “Phoenix,” but we’ll let that go—the right way. If you ask for “Chicago, IL,” for example, the Central Region’s server will give you (wait for it) the forecast for Chicago. Yes, it will give you the opportunity to change to Chicago Heights or Chicago Ridge, but only after it’s given you the forecast you asked for, which is almost certainly what you wanted. Really, if you wanted the forecast for South Phoenix, why the hell would you ask for Phoenix?]
I like having both bookmarks on my iPhone. Most of the time I’ll want the Naperville forecast, and it’s much more efficient to go there directly than through a query page. But when I’m out of town, or planning to go out of town, the query page is ready to give me a forecast for anywhere.
Feel free to adapt these scripts for your own use. If you live anywhere but in the Western Region, you should be able to customize the nws-naperville.cgi script by replacing the zipcode in Line 7. If you live in the Western Region and want a script that goes directly to your town’s forecast, you’ll have to customize nws.cgi by changing Line 23 to set place to either your zipcode or your city and state. For example, changing it to
23: place = '98039'
would be appropriate for Bill Gates.
Update
The Weather Underground has a great webapp for the iPhone at i.wund.com. It does everything my app does and more. I wrote a short description of it a few days after this post.