Twoot, again
January 22, 2009 at 12:17 PM by Dr. Drang
I’ve really been enjoying my customized version of Twoot (here’s its GitHub repository). It works the way I want it to and is easy to adjust when my needs change. Credit for that goes to:
- Peter Krantz, the creator of Twoot. If Peter hadn’t written such clean and easily understood JavaScript and CSS, I would never have dared to dig in and customize.
- John Resig, the creator of jQuery. Twoot’s clarity is a reflection of jQuery’s clarity.
- The Twitter API and its documentation. The huge number of Twitter clients is a testament not only to Twitter’s popularity, but to the simplicity of its API.
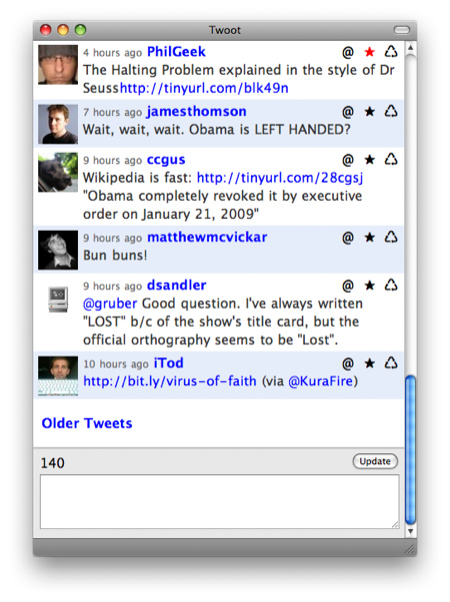
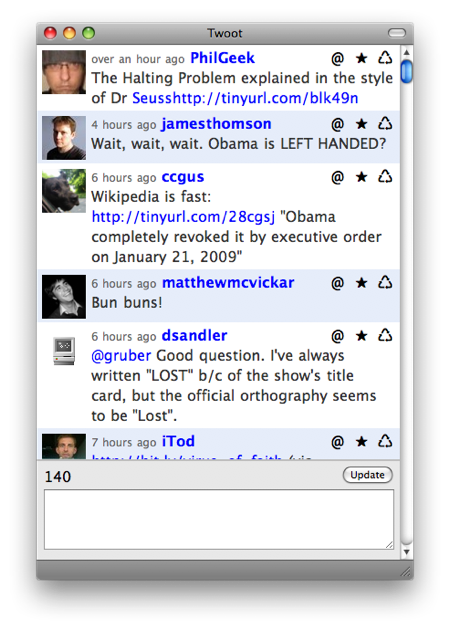
This morning, I was confronted with a bug. @PhilGeek posted a link to a funny poem/research paper, but because there was no space between the link and the preceding text, Twoot screwed up the link URL.
I knew where to go: a gnarly regular expression that looks for URLish text and turns it into a link. It started like this:
item.text.replace(/(\w+:\/\/[A-Za-z0-9-_]+…
It’s the \w+ that’s the problem. It collects all the consecutive “word” characters (letters, numbers, underscores) before the colon and double-backslash, so it ran past the “http” and grabbed the “Seuss” before it.
Obviously, the reason Peter Krantz wrote the regex that way was to be able to handle all URL types, not just http. I didn’t need or want such generality, so I changed the regex to
item.text.replace(/(http:\/\/[A-Za-z0-9-_]+…
which would recognize only http URLs. I later decided this was too restrictive and changed the regex to
item.text.replace(/((https?|ftp):\/\/[A-Za-z0-9-_]+…
which allows http, https, and ftp URLs. The runaway collection of word characters has been eliminated, and Twoot can now handle links that don’t have a preceding space or punctuation character.