
Library returns organizer
February 19, 2009 at 9:00 AM by Dr. Drang
A couple of years ago, I got a Library Elf account to keep track of all the books my family checked out from our local library. It was a great service. Every day, my wife and I would get an email or an RSS feed letting us know which books, movies, and CDs we and our kids had checked out and when they were due. Unfortunately, Library Elf recently decided to switch from an ad-based system to a subscriptions, and we dropped our account1. I decided to work out a simplified Elf-like system of my own, customized to our library.
My library offers a web-based view of each cardholder’s account: a list of the items checked out, when they are due, and an opportunity to renew.
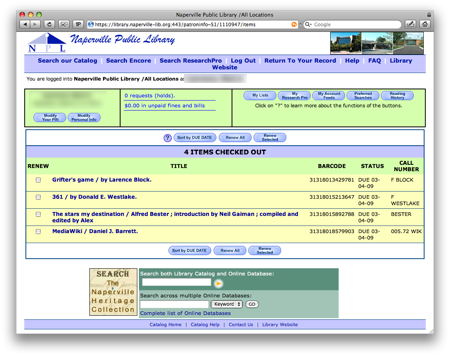
This is fine, but has two problems:
- You have to go to the library web site to see it; it’s not pushed to you.
- It doesn’t aggregate the information for all the library cards in your family.
To be fair, the library does have an email service, which will send you a reminder message 2-3 days before an item is due, so there is a push aspect to its service. But when you have a family of library users, all with several items checked out at any given time, you like to consolidate your trips to the library by gathering up and returning all the items that will be due in the next several days, not just those you’ve received an email about. This is what Library Elf excels at.
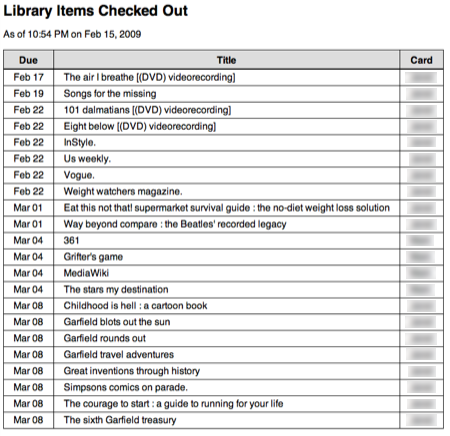
My simplified Elf-like system gathers the account information for all the library cards in our family, puts it all together into a single HTML email, and mails it to my wife and me every morning. Here’s what a typical email looks like in Apple’s Mail program
and here’s what it looks like on the iPhone
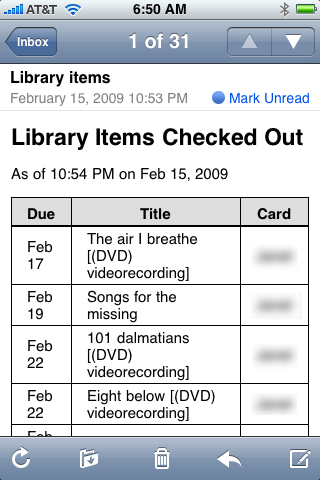
Items due on the day the email is sent (or overdue) are given a light pink background color.
My library uses the WebPAC Pro software from Innovative Interfaces. I feel certain there’s some sort of API for accessing the library database, but I’ve found no documentation for it, so I decided to collect the account information by screen scraping. The workhorse of my system is this Python script, which I call checkcards.py:
1: #!/usr/bin/python
2:
3: import mechanize
4: from BeautifulSoup import BeautifulSoup
5: from time import strptime, strftime, localtime
6:
7: # Card and email information.
8: mailFrom = 'father@example.com'
9: mailTo = 'father@example.com, mother@example.com'
10: cardList = [
11: {'patron' : 'Dad', 'formdata' : 'code=1234567890&pin=12345&submit=submit'},
12: {'patron' : 'Mom', 'formdata' : 'code=6789012345&pin=23456&submit=submit'},
13: {'patron' : 'Kid', 'formdata' : 'code=4567890123&pin=34567&submit=submit'}]
14:
15: # The URL for the library's account information.
16: URL = 'http://library.naperville-lib.org/patroninfo~S1/1110947/sorteditems'
17:
18: # Initialize the list of checked out items.
19: checkedOut = []
20:
21: # Function that returns an HTML table row of data.
22: def itemRow(data):
23: if data[0][0:3] <= localtime()[0:3]: # due today or earlier
24: classString = ' class="due"'
25: else:
26: classString = ''
27: return '''<tr%s><td>%s</td><td>%s</td><td>%s</td></tr>''' % \
28: (classString, strftime('%b %d', data[0]), data[2], data[1])
29:
30: # Go through each card, collecting the list of items checked out.
31: for card in cardList:
32: # Need to use cookies to retain the session after login.
33: cookies = mechanize.CookieJar()
34: opener = mechanize.build_opener(mechanize.HTTPCookieProcessor(cookies))
35: mechanize.install_opener(opener)
36: req = mechanize.Request(URL + '?' + card['formdata'])
37: html = mechanize.urlopen(req).read()
38:
39: # Parse the HTML.
40: soup = BeautifulSoup(html)
41:
42: # Collect the table rows that contain the items.
43: books = soup.findAll('tr', {'class' : 'patFuncEntry'})
44:
45: # Go through each row, keeping only the title and due date.
46: for book in books:
47: title = book.find('td', {'class' : 'patFuncTitle'}).a.string.split(' / ')[0].strip()
48: dueString = book.find('td', {'class' : 'patFuncStatus'}).contents[0].replace('DUE', '').strip()
49: due = strptime(dueString, '%m-%d-%y')
50: # Add the item to the checked out list
51: checkedOut.append((due, card['patron'], title))
52:
53: # Sort the list by due date, then patron, then title.
54: checkedOut.sort()
55:
56: # Templates for the email.
57: mailTop = '''From: %s
58: To: %s
59: Subject: Library items
60: Content-Type: text/html
61:
62: <html>
63: <head>
64: <style type="text/css">
65: body {
66: font-family: Helvetica, Sans-serif;
67: }
68: h1 {
69: font-size: 150%%;
70: }
71: table {
72: border-collapse: collapse;
73: }
74: table th {
75: padding: .5em 1em .25em 1em;
76: background-color: #ddd;
77: border: 1px solid black;
78: border-bottom: 2px solid black;
79: }
80: table th.due {
81: background-color: #fcc;
82: }
83: table td {
84: padding: .25em 1em .25em 1em;
85: border: 1px solid black;
86: }
87: </style>
88: </head>
89: <body>
90: <h1>Library Items Checked Out</h1>
91: <p>As of %s</p>
92: <table>
93: <tr><th>Due</th><th>Title</th><th>Card</th></tr>'''
94:
95: mailBottom = '''</table>
96: </body>
97: </html>'''
98:
99: # Print out the email header and contents. This should be piped to sendmail.
100: print mailTop % (mailFrom, mailTo, strftime('%I:%M %p on %b %d, %Y'))
101: print '\n'.join([itemRow(x) for x in checkedOut])
102: print mailBottom
The script uses the mechanize and Beautiful Soup libraries. Neither of these are in the standard Python distribution; they must be downloaded and installed before running the script.
Lines 7-13 contain information specific to the family: the email addresses to which the daily notices are sent, and the library card numbers and PINs for each user. The card numbers and PINs are used by the script to log in and get to the pages with the account information.
The URL in Line 16 is rather odd, and it isn’t the URL you go to to log in. I had to do some experimenting with curl in verbose mode on the command line to figure out which URL to use here.
Lines 32-37 log in to the library site using the features of the mechanize library. WebPAC Pro uses session cookies to keep the user logged in, and the mechanize library receives and retrieves the cookies, as appropriate.
Beautiful Soup then parses the HTML of the page (like the page in the screen shot above). The information of interest is in the table in the middle of the page, the rows of which have a class attribute of patFuncEntry. Line 43 collects these rows, one for each item checked out.
Lines 45-51 then go through the cells of each row, grabbing only the data of interest, namely, the title and due date of the item. The title and author of a book are in the same cell, separated by a slash; Line 47 uses this fact to keep only the title. Line 49 converts the date string from the web page into a Python time tuple. In Line 51, the collected data and the patron name are put together in a tuple and appended to the checkedOut list.
After the information is gathered for each card, the checkedOut list is sorted. Because each item in the list is a tuple in “date, patron, title” order, the list is sorted first by due date, then by patron name, then by title. This seemed like the best way to order the items in the email.
The rest of the script is just printing. Lines 56-60 are the mail header. Lines 64-87 define the CSS style for the emails HTML content. The data for each item are taken from the checkedOut list and are passed through the itemRow function (Lines 22-28) to arrange the data in an HTML table row.
The output of checkcards.py is written to be piped to sendmail. I have a simple shell script, called checkcards, that does this:
#!/bin/bash
python /Users/drang/bin/checkcards.py | /usr/sbin/sendmail -t
On my Mac, checkcards is run daily via the launchd mechanism. I used Lingon, by Peter Borg (more widely known for the Smultron text editor), to set up the necessary launchd plist. If I were running this on a Linux machine, I would set up a cron job. On Windows, I’d use a Scheduled Task2.
So far, checkcards is working well. Like all screen scrapers, its continued functioning depends on an unchanging underlying web page. Since my library just went through a major IT infrastructure overhaul last year, I expect no changes for quite a while. checkcards could be improved by:
- Including a section for items on hold.
- Extending the pink “warning” color to items due tomorrow in addition to today.
- Putting links to the library’s account pages in the email to make renewals just a click or two away.
- Creating an RSS feed in addition to the email.
Of these, adding the items on hold seems the most useful.
If your library uses WebPAC Pro, you could probably adapt checkcards.py to your own situation; you’d have to use your own login credentials, of course, and also figure out the correct URL to use with mechanize.Request. If your library uses different access software, you’re more on your own, but the outline of your script will be the same:
for each card:
log in to the library
go to the page that shows the items checked out
collect the item and due date information and put them in a list
sort the list of items checked out
print out the list in a form that can be emailed.
Update (2/27/09)
The script now tracks library items put on hold. The new version is here.
-
I have suggested to our library that it get a subscription, which would benefit all its patrons, but they haven’t done so yet. ↩
-
I’m pretty sure Windows doesn’t have sendmail, so I’d need some other way of mailing the output of
checkcards.py. If sendmail comes with Cygwin that would make things easier. ↩