
Updated Twitter-to-blog script
July 14, 2009 at 11:53 AM by Dr. Drang
Back in October I wrote a script that would collect all my Twitter updates from the previous day and create a blog post from them. As the months have gone by, I’ve found and fixed some bugs and added a feature or two. I decided it would be a good idea to post the updated script.
The main goal of script hasn’t changed since my original post:
First, some motivation for the script. For a few months now, I’ve been including my recent Twitter posts in the sidebar over at the right. I followed the directions Twitter gives, following the HTML/JavaScript method so I could use CSS to style the tweets and match the look of the site. It’s easy, but it does tend to put the tweets in a ghetto. They’re out of sync with the regular posts and don’t get archived. Since many of my tweets would have been tiny blog posts in the pre-Twitter days, I thought they should be added like regular posts.
On the other hand, I didn’t want every tweet to have its own post. A daily collection of tweets seemed like the best compromise. My goal was to write a program that would run every day, gathering all the tweets of the previous day and putting them into a single post, timestamped and separated by blank lines.
A secondary goal has arisen since October: I’ve noticed that Twitter’s search doesn’t work well for older tweets, which makes it hard to find what you wrote months ago. For example, on April 25 I was hit by a pickup truck while riding my bike, and I tweeted about it when I got home an hour or so later. Using search.twitter.com to find posts written by me in April with the word “pickup” comes up empty. But if I type “pickup” in the little search field over to the right, I quickly find the automatic post that contains that tweet. It’s not that the tweet has been erased by Twitter—here it is—it’s that Twitter’s search engine won’t find it. So the automatic posts act as an easily-searchable archive of my tweets.
The script, which I call twitterpost, relies on four nonstandard Python libraries
- python-twitter, which communicates with the Twitter API;
- simplejson, which is used by python-twitter;
- pytz, which handles the timezone conversions; and
- wordpresslib, which communicates with the blog.
Here’s the source for twitterpost itself:
1 #!/usr/bin/python
2
3 import twitter
4 from datetime import datetime, timedelta
5 import pytz
6 import wordpresslib
7 import sys
8 import re
9
10 # Parameters.
11 tname = 'drdrang' # the Twitter username
12 chrono = True # should tweets be in chronological order?
13 replies = False # should Replies be included in the post?
14 burl = 'http://www.leancrew.com/all-this/xmlrpc.php' # the blog xmlrpc URL
15 bid = 0 # the blog id
16 bname = 'drdrang' # the blog username
17 bpword = 'blahblahblahblah' # the blog password (no, that's not my real password)
18 bcat = 'personal' # the blog category
19 tz = pytz.timezone('US/Central') # the blog timezone
20 utc = pytz.timezone('UTC')
21
22 # Get the starting and ending times for the range of tweets we want to collect.
23 # Since this is supposed to collect "yesterday's" tweets, we need to go back
24 # to 12:00 am of the previous day. For example, if today is Thursday, we want
25 # to start at the midnight that divides Tuesday and Wednesday. All of this is
26 # in local time.
27 yesterday = datetime.now(tz) - timedelta(days=1)
28 starttime = yesterday.replace(hour=0, minute=0, second=0, microsecond=0)
29 endtime = starttime + timedelta(days=1)
30
31 # Create a regular expression object for detecting URLs in the body of a tweet.
32 # Adapted from
33 # http://immike.net/blog/2007/04/06/5-regular-expressions-every-web-programmer-should-know/
34 url = re.compile(r'''(https?://[-\w]+(\.\w[-\w]*)+(/[^.!,?;"'<>()\[\]\{\}\s\x7F-\xFF]*([.!,?]+[^.!,?;"'<>()\[\]\{\}\s\x7F-\xFF]+)*)?)''', re.I)
35
36 # A regular expression object for initial hash marks (#). These must
37 # be escaped so Markdown doesn't interpret them as a heading.
38 hashmark = re.compile(r'^#', re.M)
39
40 ##### Twitter interaction #####
41
42 # Get all the available tweets from the given user. By default, they're in
43 # reverse chronological order. The 'since' parameter of GetUserTimeline could
44 # be used to limit the collection to recent tweets, but because tweets are kept
45 # in UTC, and we want them filtered according to local time, we'd have to
46 # filter them again anyway. So it doesn't seem worth the bother.
47 api = twitter.Api()
48 statuses = api.GetUserTimeline(user=tname)
49
50 if chrono:
51 statuses.reverse()
52
53 # Collect every tweet and its timestamp in the desired time range into a list.
54 # The Twitter API returns a tweet's posting time as a string like
55 # "Sun Oct 19 20:14:40 +0000 2008." Convert that string into a timezone-aware
56 # datetime object, then convert it to local time. Filter according to the
57 # start and end times.
58 tweets = []
59 for s in statuses:
60 posted_text = s.GetCreatedAt()
61 posted_utc = datetime.strptime(posted_text, '%a %b %d %H:%M:%S +0000 %Y').replace(tzinfo=utc)
62 posted_local = posted_utc.astimezone(tz)
63 if (posted_local >= starttime) and (posted_local < endtime):
64 timestamp = posted_local.strftime('%I:%M %p').lower()
65 # Add or escape Markdown syntax.
66 body = url.sub(r'<\1>', s.GetText()) # URLs
67 body = hashmark.sub(r'\#', body) # initial hashmarks
68 body = body.replace('\n', ' \n') # embedded newlines
69 if replies or body[0] != '@':
70 if timestamp[0] == '0':
71 timestamp = timestamp[1:]
72 tweet = '[**%s**](http://twitter.com/%s/statuses/%s) \n%s\n' % (timestamp, tname, s.GetId(), body)
73 tweets.append(tweet)
74
75 # Obviously, we can quit if there were no tweets.
76 if len(tweets) == 0:
77 print 0
78 sys.exit()
79
80 # A line for the end directing readers to the post with this program.
81 lastline = """
82
83 *This post was generated automatically using the script described [here](http://www.leancrew.com/all-this/2009/07/updated-twitter-to-blog-script/).*
84 """
85
86 # Uncomment the following 2 lines to see the output w/o making a blog post.
87 # print '\n'.join(tweets) + lastline
88 # sys.exit()
89
90 ##### Blog interaction #####
91
92 # Connect to the blog.
93 blog = wordpresslib.WordPressClient(burl, bname, bpword)
94 blog.selectBlog(bid)
95
96 # Create the info we're going to post.
97 post = wordpresslib.WordPressPost()
98 post.title = 'Tweets for %s' % yesterday.strftime('%B %e, %Y')
99 post.description = '\n'.join(tweets) + lastline
100 post.categories = (blog.getCategoryIdFromName(bcat),)
101
102 # And post it.
103 newpost = blog.newPost(post, True)
104 print newpost
The main differences with the original twitterpost are:
- Line 67 escapes hashmarks (#) at the beginnings of lines to avoid a conflict with Markdown headers. I use Markdown to format my posts.
- Line 68 forces linebreaks when there are newline characters in the tweet.
- Line 72 turns the timestamp into a link to the tweet on twitter.com. Thisis the most recent addition; it will go into effect tomorrow.
A description of the rest of the script can be found in the original post.
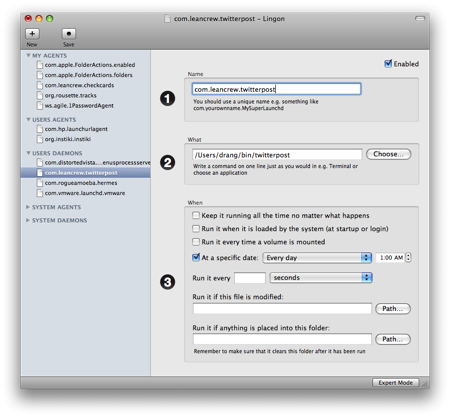
The script is run every day at 1:00 am by launchd. I use Lingon to configure launchd.
If you subscribe to my RSS feed and don’t want to see the twitterpost entries, you can use this Yahoo! Pipes feed, written by Patrick Mosby to filter them out.