
PDFs and JPEGs again
November 24, 2009 at 10:54 PM by Dr. Drang
So I tried that pdf2jpg script today at work and it failed. Oh, it made a JPEG for every page of the PDF I gave it, but the JPEGs were at only a 72 dpi resolution. That’s 792×612, not nearly enough for a decent print. What went wrong?
Well, in one sense, nothing went wrong. The script still works on my iBook G4 running Leopard, which is where I used it last week. Today’s failure occurred on my office computer, which is an Intel iMac running Snow Leopard. I really doubt the processor has anything to do with the difference in behavior; my guess is that something has changed in either Cocoa or PyObjC.
Here’s the pdf2jpg script again:
1: #!/usr/bin/python
2:
3: # author: Martin Michel
4: # eMail: martin.michel@macscripter.net
5: # created: 01.04.2008
6: # modified by Dr. Drang (drdrang@gmail.com) 2009-11-20
7:
8: # Thanks to Dinu C. Gherman for providing the
9: # code example on http://python.net/~gherman/pdf2tiff.html
10:
11: import sys
12: import os
13: from os.path import splitext
14: from objc import YES, NO
15: from Foundation import NSData
16: from AppKit import *
17:
18: NSApp = NSApplication.sharedApplication()
19:
20: def pdf2jpg(pdfpath, resolution=300):
21: """I am converting all pages of a PDF file to JPG images."""
22:
23: pdfdata = NSData.dataWithContentsOfFile_(pdfpath)
24: pdfrep = NSPDFImageRep.imageRepWithData_(pdfdata)
25: pagecount = pdfrep.pageCount()
26: for i in range(0, pagecount):
27: pdfrep.setCurrentPage_(i)
28: pdfimage = NSImage.alloc().init()
29: pdfimage.addRepresentation_(pdfrep)
30: origsize = pdfimage.size()
31: width, height = origsize
32: pdfimage.setScalesWhenResized_(YES)
33: rf = resolution / 72.0
34: pdfimage.setSize_((width*rf, height*rf))
35: tiffimg = pdfimage.TIFFRepresentation()
36: bmpimg = NSBitmapImageRep.imageRepWithData_(tiffimg)
37: data = bmpimg.representationUsingType_properties_(NSJPEGFileType, {NSImageCompressionFactor: 1.0})
38: jpgpath = "%s-%02d.jpg" % (splitext(pdfpath)[0], i+1)
39: if not os.path.exists(jpgpath):
40: data.writeToFile_atomically_(jpgpath, False)
41:
42: if __name__ == '__main__':
43: for pdfpath in sys.argv[1:]:
44: pdf2jpg(pdfpath)
The resolution of the JPEG is set in Lines 33-37, where the image of the PDF page is supposed to be upsized (Lines 33-34), made into a TIFF image (Line 35), and then converted into a JPEG, (Lines 36-37). After a bit of experimentation involving writing out TIFF files before the JPEG conversion, it appears to me that the problem is in Line 35: the TIFF image isn’t being created at the 300 dpi resolution. So there’s either something different in Snow Leopard’s version TIFFRepresentation, or the PyObjC that comes with Snow Leopard is calling it wrong. Maybe the setScalesWhenResized_ call in Line 32 isn’t working right.
Or maybe my diagnosis is completely off and the problem lies somewhere else entirely.
So how can I convert multipage PDFs to a series of JPEGs when I’m at work? It turns out that Automator, which last week I couldn’t get to do the conversion on the iBook (but see below), can do the conversion just fine on the iMac. Here’s what the workflow looks like:
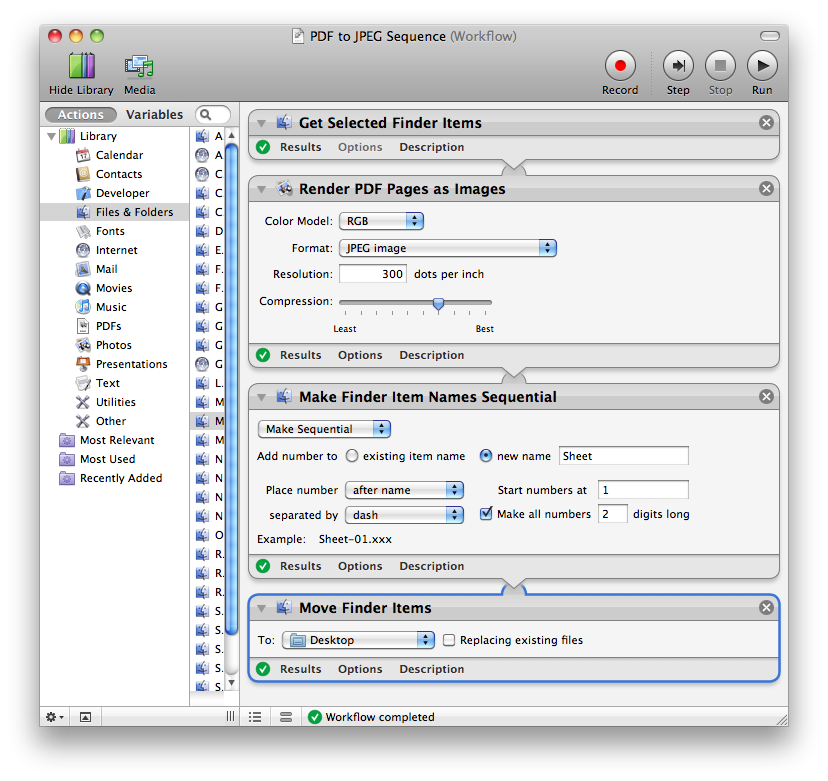
This isn’t the greatest solution in the world, because every new file is called “Sheet-xx.jpeg” instead of taking its name from the original PDF, but I suppose that can be fixed by adding an AppleScript or shell script to the workflow. Or, conversely, maybe the workflow can be called from a script that handles the names. Even if the names stay as they are, at least I’ve got the JPEGs I need.
And about the Automator workflow not performing on my iBook? Well…er…I tried it again tonight, and it worked just fine. Don’t know what I was doing wrong last week.
So now I’m left with at decision: should I try to get pdf2jpg to work on the iMac, or should I try to improve the file naming in the Automator workflow. The former appeals to me because I might actually learn something about Cocoa or PyObjC, but the latter seems more likely to yield quick results.