
Improved library loan tracker
February 27, 2009 at 9:30 PM by Dr. Drang
For reasons not entirely clear to me, my local library’s web site went through some gyrations today that broke my library loan tracking script. Early this morning, when I first noticed the problem, the changes to the site were so great that I dreaded the work it would take to fix the script. By this evening, when I had a chance to look into the problem in depth, the site had changed again. Luckily, though, the second change brought back almost to its original state. The changes I had to make to get the script running again were fairly minor.
The current script does, however, differ significantly from the one presented in my earlier post, because last weekend I added the ability to track items on hold. So now my wife and I get an email each morning with:
- A list of all the library items loaned to us and our kids, sorted by due date.
- A list of all the items we’ve put on hold, sorted by our place in the hold queue.
On the iPhone, the list of checked-out items looks like this
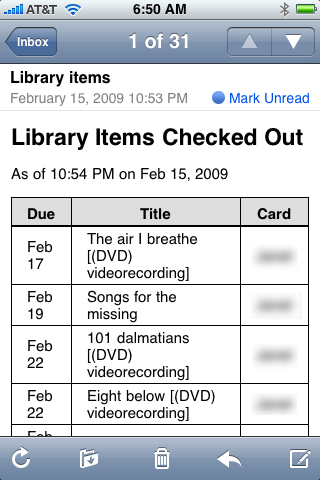
and the list of holds looks like this1
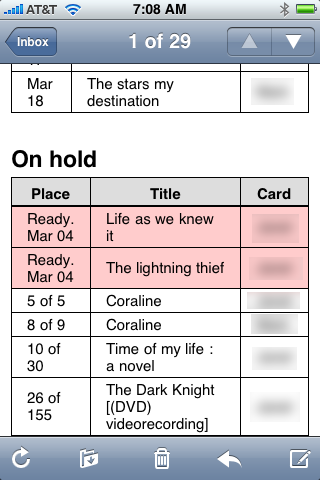
Holds that are ready for pickup are given a pink background; items that are due or overdue are given the same background.
The motivation for my setting up this system is described in that earlier post. In a nutshell, we used to get this information through Library Elf, but we dropped our Library Elf account when it shifted from an ad-based to a subscription-based revenue model.
All the differences are in checkcards.py. Here’s the current version.
1: #!/usr/bin/python
2:
3: import mechanize
4: from BeautifulSoup import BeautifulSoup
5: from time import strptime, strftime, localtime
6: import re
7:
8: # Card and email information.
9: mailFrom = 'father@example.com'
10: mailTo = 'father@example.com, mother@example.com'
11: cardList = [
12: {'patron' : 'Dad', 'formdata' : 'code=1234567890&pin=12345'},
13: {'patron' : 'Mom', 'formdata' : 'code=6789012345&pin=23456'},
14: {'patron' : 'Kid', 'formdata' : 'code=4567890123&pin=34567'}]
15:
16: # The URL for the library's account information.
17: cURL = 'http://library.naperville-lib.org/patroninfo~S1/1110947/items' # checked out
18: hURL = 'http://library.naperville-lib.org/patroninfo~S1/1110947/holds' # on hold
19:
20: # Initialize the lists of checked-out and on-hold items.
21: checkedOut = []
22: onHold = []
23:
24: # Function that returns an HTML table row for checked out items.
25: def cRow(data):
26: if data[0][0:3] <= localtime()[0:3]: # due today or earlier
27: classString = ' class="due"'
28: else:
29: classString = ''
30: return '''<tr%s><td>%s</td><td>%s</td><td>%s</td></tr>''' % \
31: (classString, strftime('%b %d', data[0]), data[2], data[1])
32:
33: # Function that returns an HTML table row for items on hold.
34: def hRow(data):
35: if data[0] <= 0: # Waiting for pickup or in transit
36: classString = ' class="due"'
37: else:
38: classString = ''
39: return '''<tr%s><td>%s</td><td>%s</td><td>%s</td></tr>''' % \
40: (classString, data[3], data[2], data[1])
41:
42: # Go through each card, collecting the lists of items.
43: for card in cardList:
44: # Need to use cookies to retain the session after login.
45: cookies = mechanize.CookieJar()
46: opener = mechanize.build_opener(mechanize.HTTPCookieProcessor(cookies))
47: mechanize.install_opener(opener)
48:
49: # Go get the pages.
50: cReq = mechanize.Request(cURL + '?' + card['formdata'])
51: cHtml = mechanize.urlopen(cReq).read()
52: # print cHtml
53: # sys.exit()
54: hReq = mechanize.Request(hURL + '?' + card['formdata'])
55: hHtml = mechanize.urlopen(hReq).read()
56:
57: # Parse the HTML.
58: cSoup = BeautifulSoup(cHtml)
59: hSoup = BeautifulSoup(hHtml)
60:
61: # Collect the table rows that contain the items.
62: outs = cSoup.findAll('tr', {'class' : 'patFuncEntry'})
63: holds = hSoup.findAll('tr', {'class' : 'patFuncEntry'})
64:
65: # Due dates and pickup dates are of the form mm-dd-yy.
66: dueDate = re.compile(r'\d\d-\d\d-\d\d')
67:
68: # Go through each row of checked out items, keeping only the title and due date.
69: for item in outs:
70: # The title is everything before the spaced slash in the patFuncTitle cell.
71: title = item.find('td', {'class' : 'patFuncTitle'}).a.string.split(' / ')[0].strip()
72: # The due date is somewhere in the patFuncStatus cell.
73: dueString = dueDate.findall(item.find('td', {'class' : 'patFuncStatus'}).contents[0])[0]
74: due = strptime(dueString, '%m-%d-%y')
75: # Add the item to the checked out list. Arrange tuple so items
76: # get sorted by due date.
77: checkedOut.append((due, card['patron'], title))
78:
79: # Go through each row of holds, keeping only the title and place in line.
80: for item in holds:
81: # Again, the title is everything before the spaced slash.
82: title = item.find('td', {'class' : 'patFuncTitle'}).a.string.split(' / ')[0].strip()
83: # The book's status in the hold queue will be either:
84: # 1. 'n of m holds'
85: # 2. 'Ready. Must be picked up by mm-dd-yy'
86: # 3. 'IN TRANSIT'
87: status = item.find('td', {'class' : 'patFuncStatus'}).contents[0].strip()
88: n = status.split()[0]
89: if n.isdigit(): # possibility 1
90: n = int(n)
91: status = status.replace(' holds', '')
92: elif n[:5] == 'Ready': # possibility 2
93: n = -1
94: dueString = dueDate.findall(status)[0]
95: status = 'Ready<br/> ' + strftime('%b %d', strptime(dueString, '%m-%d-%y'))
96: else: # possibility 3
97: n = 0
98: # Add the item to the on hold list. Arrange tuple so items
99: # get sorted by position in queue. The position is faked for
100: # items ready for pickup and in transit within the library.
101: onHold.append((n, card['patron'], title, status))
102:
103: # Sort the lists.
104: checkedOut.sort()
105: onHold.sort()
106:
107: # Templates for the email.
108: mailHeader = '''From: %s
109: To: %s
110: Subject: Library items
111: Content-Type: text/html
112: '''
113:
114: pageHeader = '''<html>
115: <head>
116: <style type="text/css">
117: body {
118: font-family: Helvetica, Sans-serif;
119: }
120: h1 {
121: font-size: 150%%;
122: margin-top: 1.5em;
123: margin-bottom: .25em;
124: }
125: table {
126: border-collapse: collapse;
127: }
128: table th {
129: padding: .5em 1em .25em 1em;
130: background-color: #ddd;
131: border: 1px solid black;
132: border-bottom: 2px solid black;
133: }
134: table tr.due {
135: background-color: #fcc;
136: }
137: table td {
138: padding: .25em 1em .25em 1em;
139: border: 1px solid black;
140: }
141: </style>
142: </head>
143: <body>
144: <p>As of %s</p>
145: '''
146:
147: tableTemplate = '''<h1>%s</h1>
148: <table>
149: <tr><th>%s</th><th>Title</th><th>Card</th></tr>
150: %s
151: </table>
152: '''
153:
154: pageFooter = '''</body>
155: </html>'''
156:
157: # Print out the email header and contents. This should be piped to sendmail.
158: print mailHeader % (mailFrom, mailTo)
159: print pageHeader % strftime('%I:%M %p on %b %d, %Y')
160: print tableTemplate % ('Checked out', 'Due', '\n'.join([cRow(x) for x in checkedOut]))
161: print tableTemplate % ('On hold', 'Status', '\n'.join([hRow(x) for x in onHold]))
162: print pageFooter
Now there are two pages that must be visited and screen-scraped for each library card: the loaned items page and the holds page. In revisiting the script, I realized that the comments were pretty skimpy, so they’ve been beefed up. Also, if you compare this script with the original, you’ll see that I’ve refactored some of the HTML generation code to make it easier to generate two tables of data.
-
My wife and I both put Coraline on hold after we saw the movie. She got the better spot in the queue. ↩