
An unfair review of Learning JavaScript
January 23, 2007 at 12:23 AM by Dr. Drang
In my quest to learn JavaScript, I’ve checked out a few books from the local library, and skimmed through them to see if I should buy any of them. One of them is Learning JavaScript , a new O’Reilly book written by Shelley Powers.
Time was when the O’Reilly name pretty much guaranteed that a book was worth your money. I can’t remember a clunker in the half-dozen or so that I bought in the mid-to-late 90s. But now you have to do your homework to make sure you’re not left with dust collector with an animal on the front.
So while I was skimming Learning JavaScript I ran across this on page 28:
The term CamelCase is based on the popularity of mixed upper- and lower-case letters in Perl, and of the camel featured on the cover of the bestselling book, Programming Perl, by Larry Wall, et al. (O’Reilly). Wikipedia has a fascinating and dynamic article on this and other naming notions at http://en.wikipedia.org/wiki/CamelCase.
There are at least three errors in these two sentences. First, CamelCase clearly refers to the up-and-down shape of mixed-case names being reminiscent of a camel’s humps. Second, I own all three editions of Programming Perl, as well as Learning Perl (first edition, I think), Perl Cookbook, Perl Best Practices, and a few others whose names I can’t remember right now, and it’s clear that the big gun Perl programmers prefer underscore_names, not CamelCase. Third, the Wikipedia entry for CamelCase does not support Powers’ explanation, it refutes it:
The name CamelCase is not related to the “Camel book” (Programming Perl), which uses all-lowercase identifiers with underscores in its sample code.
Now, I suppose the Wikipedia article could have been mistaken back when Powers was writing the book, but how could an O’Reilly writer (and an O’Reilly editor) make such a fundamental error about one of the flagship O’Reilly titles?
OK, I thought, a stupid mistake, but on kind of a peripheral issue. Let’s move on. I went no farther than page 29—the facing page—when I ran into this:
Iterator variables (used in
forloops and other looping mechanisms) should be simple, and consist of i, j, k, and so on, down the alphabet (a holdover from long, long ago when programming languages such as FORTRAN required that all integers begin with the letters i, j, etc.).
First, Fortran, did not require integers to “begin with the letters i, j, etc.” (and how far is that etc. supposed to take us, eh?). It is true that if you chose not to declare variable types, variables with names that started with the letters i through n would be taken as integers, but you were free to start your variable names with any letter if declared those variables. More important, though, letters like i, j, and k are the common looping variables because they are the common indexing subscripts in mathematics: ui, Aij. They’re also common as the indexing variables in sums and products like this:
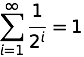
The relationship between the mathematical process of summation and the programming task of looping is, I think, pretty obvious. So the use of i, j, and k for looping variables is not an homage to John Backus, it’s a reflection of the mathematical roots of programming.
Now I could take this i, j, k thing in stride and move on, as before. Naming conventions aren’t JavaScript, after all. But two silly mistakes within a handful of paragraphs is just too much for me. If neither Ms. Powers nor her editor can be bothered with getting a few simple facts straight, I can’t be bothered with reading, let alone buying, their book. If they get wrong the things I know, how can I trust them on the things I don’t know?