
Updated Twitter posting and an apology
September 12, 2009 at 8:43 AM by Dr. Drang
Let’s start with the apology. Earlier this week, RSS subscribers got repeated notices of the daily roundup of my Twitter updates. These posts are generated automatically overnight; because of a screwup on my part, two posts were being made each day and the feeds followed suit. I’m sorry about that. It took me a couple of days to figure out what was wrong, but it seems to be fixed now.
The screwup came as I was trying to make the twitterpost script more robust. When it’s working, twitterpost
- Connects to Twitter and collects my recent tweets.
- Sorts through them and retains only those that were written the previous day.
- Puts them in chronological order.
- Generates and uploads a post to the blog.
I have a launchd process set up to run twitterpost in the middle of the night to automatically generate a blog post of my deathless thoughts. But it had stopped working well.
You may recall that at the beginning of the month Twitter was quite unreliable—more so than usual. For several days in a row, twitterpost had been unable to connect when it ran, so it would just fail, and there’d be no automatic posting for that day. I’d have to run the script by hand when Twitter was responsive. To fix this problem, I rewrote twitterpost to check whether the connection was successful and try again several minutes later if it wasn’t. Here’s the new source code:
1: #!/usr/bin/python
2:
3: import twitter
4: from datetime import datetime, timedelta
5: from time import sleep
6: import pytz
7: import wordpresslib
8: import sys
9: import re
10:
11: # Parameters.
12: tname = 'drdrang' # the Twitter username
13: chrono = True # should tweets be in chronological order?
14: replies = False # should Replies be included in the post?
15: burl = 'http://www.leancrew.com/all-this/xmlrpc.php' # the blog xmlrpc URL
16: bid = 0 # the blog id
17: bname = 'drdrang' # the blog username
18: bpword = 'seekret' # not the real blog password
19: bcat = 'personal' # the blog category
20: tz = pytz.timezone('US/Central') # the blog timezone
21: utc = pytz.timezone('UTC')
22:
23: # Get the starting and ending times for the range of tweets we want to collect.
24: # Since this is supposed to collect "yesterday's" tweets, we need to go back
25: # to 12:00 am of the previous day. For example, if today is Thursday, we want
26: # to start at the midnight that divides Tuesday and Wednesday. All of this is
27: # in local time.
28: yesterday = datetime.now(tz) - timedelta(days=1)
29: starttime = yesterday.replace(hour=0, minute=0, second=0, microsecond=0)
30: endtime = starttime + timedelta(days=1)
31:
32: # Create a regular expression object for detecting URLs in the body of a tweet.
33: # Adapted from
34: # http://immike.net/blog/2007/04/06/5-regular-expressions-every-web-programmer-should-know/
35: url = re.compile(r'''(https?://[-\w]+(\.\w[-\w]*)+(/[^.!,?;"'<>()\[\]\{\}\s\x7F-\xFF]*([.!,?]+[^.!,?;"'<>()\[\]\{\}\s\x7F-\xFF]+)*)?)''', re.I)
36:
37: # A regular expression object for initial hash marks (#). These must
38: # be escaped so Markdown doesn't interpret them as a heading.
39: hashmark = re.compile(r'^#', re.M)
40:
41: ##### Twitter interaction #####
42:
43: # Get all the available tweets from the given user. If Twitter is unresponsive,
44: # wait a while and try again. If it's still unreponsive after several tries,
45: # just give up.
46: api = twitter.Api()
47: tries = 9
48: trial = 0
49: while trial < tries:
50: trial += 1
51: try:
52: statuses = api.GetUserTimeline(user=tname)
53: except:
54: print "Can't connect to Twitter on try %d..." % trial
55: sleep(15*60)
56: continue
57: break
58: if trial >= tries:
59: print 0
60: sys.exit()
61:
62: # Tweets are in reverse chronological order by default.
63: if chrono:
64: statuses.reverse()
65:
66: # Collect every tweet and its timestamp in the desired time range into a list.
67: # The Twitter API returns a tweet's posting time as a string like
68: # "Sun Oct 19 20:14:40 +0000 2008." Convert that string into a timezone-aware
69: # datetime object, then convert it to local time. Filter according to the
70: # start and end times.
71: tweets = []
72: for s in statuses:
73: posted_text = s.GetCreatedAt()
74: posted_utc = datetime.strptime(posted_text, '%a %b %d %H:%M:%S +0000 %Y').replace(tzinfo=utc)
75: posted_local = posted_utc.astimezone(tz)
76: if (posted_local >= starttime) and (posted_local < endtime):
77: timestamp = posted_local.strftime('%I:%M %p').lower()
78: # Add or escape Markdown syntax.
79: body = url.sub(r'<\1>', s.GetText()) # URLs
80: body = hashmark.sub(r'\#', body) # initial hashmarks
81: body = body.replace('\n', ' \n') # embedded newlines
82: if replies or body[0] != '@':
83: if timestamp[0] == '0':
84: timestamp = timestamp[1:]
85: tweet = '[**%s**](http://twitter.com/%s/statuses/%s) \n%s\n' % (timestamp, tname, s.GetId(), body)
86: tweets.append(tweet)
87:
88: # Obviously, we can quit if there were no tweets.
89: if len(tweets) == 0:
90: print 0
91: sys.exit()
92:
93: # A line for the end directing readers to the post with this program.
94: lastline = """
95:
96: *This post was generated automatically using the script described [here](http://www.leancrew.com/all-this/2009/07/updated-twitter-to-blog-script/).*
97: """
98:
99: # Uncomment the following 2 lines to see the output w/o making a blog post.
100: # print '\n'.join(tweets) + lastline
101: # sys.exit()
102:
103: ##### Blog interaction #####
104:
105: # Connect to the blog.
106: blog = wordpresslib.WordPressClient(burl, bname, bpword)
107: blog.selectBlog(bid)
108:
109: # Create the info we're going to post.
110: post = wordpresslib.WordPressPost()
111: post.title = 'Tweets for %s' % yesterday.strftime('%B %e, %Y')
112: post.description = '\n'.join(tweets) + lastline
113: post.categories = (blog.getCategoryIdFromName(bcat),)
114:
115: # And post it.
116: newpost = blog.newPost(post, True)
117: print newpost
The new stuff is in Lines 43-60. The connection to Twitter is now in the body of a loop. If the connection fails, the connection attempt is repeated 15 minutes later, for a maximum of 9 attempts over a two-hour period. If the connection succeeds, the process breaks out of the loop and continues on to create the post.
I tested the new twitterpost by running it with my network cable initially disconnected (Twitter wouldn’t oblige me by being down during testing). After a few loops, I’d reconnect the cable and the rest of the script would execute. It seemed to be working perfectly, so I was surprised to find the repeated posts the next day.
My first thought was that some mistake in the loop was making the script stutter. But it wouldn’t stutter when I tested it, and the connection to the blog wasn’t even in the loop. Eventually I learned that I had somehow created a second launchd process; the posts were repeated because twitterpost was being run twice each night. Killing the second launchd process eliminated the repeated post.
Update 9/15/09
Hey, it works! Last night, the script couldn’t connect to Twitter for an hour. I have it set to start at 1:15 am, but last night’s post is timestamped 2:15 am. Launching Console to look at the system log, I found this:
Sep 15 02:15:05 drang com.leancrew.twitterpost[45665]: Can't connect to Twitter on try 1...
Sep 15 02:15:05 drang com.leancrew.twitterpost[45665]: Can't connect to Twitter on try 2...
Sep 15 02:15:05 drang com.leancrew.twitterpost[45665]: Can't connect to Twitter on try 3...
Sep 15 02:15:05 drang com.leancrew.twitterpost[45665]: Can't connect to Twitter on try 4...
Sep 15 02:15:05 drang com.leancrew.twitterpost[45665]: 998
Four failures and then a success. I know the timestamps make it look like all the attempts were made at 2:15, but that’s because the script doesn’t flush its output as it runs; all the output hits the system log when script finishes. I saw the same thing when I was testing the script with the network cable disconnected.
I did my best to simulate a failed connection in my testing, and I thought it would work, but it’s still nice to see it doing what it’s supposed to in a real world situation.
Because I felt bad about sending out repeated feeds, and because I began to question the value of these automatic tweet posts, I decided to create new feeds that excluded the Twitter posts. Patrick Mosby had already done this through Yahoo! Pipes, and my first thought was to just link to his feed. But I didn’t want to be dependent on his maintaining that feed, so I just copied his work on my own Yahoo! account.
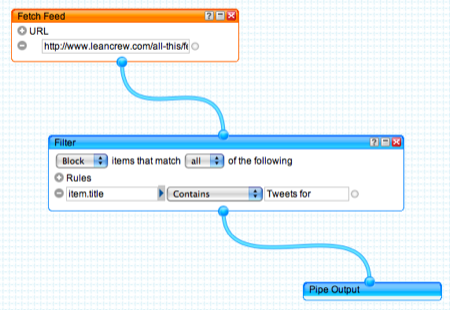
So now there are four feeds: an RSS 2.0 feed with every post, an Atom feed with every post, an RSS 2.0 feed without the Twitter posts, and an Atom feed without the Twitter posts.
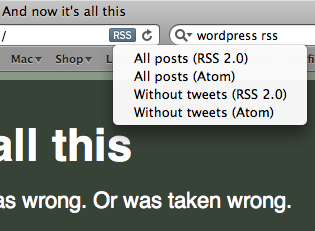
I’ve never understood the niceties of RSS 2.0 v. Atom, but since WordPress and Yahoo! Pipes make it easy to provide both, that’s what I’ll do.